publicado por Iván Mérida el 16 de junio, 2021.
Introducción
Los sistemas gestores de bases han ido evolucionando con el paso del tiempo y adaptándose a los nuevos requerimientos y estándares que se usan actualmente, muchos son los gestores que existen en el mercado y cada uno fue hecho para cumplir una tarea en específica, dicha tarea es la misma; la de gestionar y almacenar los datos que se vayan agregando a este, pero, en donde este proceso es diferente, es el funcionamiento de estos, muchos fueron creadas para unos exclusivo de grandes corporaciones y sus planes incluyen muchos más protocolos de seguridad que los que son open source o mantenidos por la comunidad o empresa sin fines de lucro, estos sistemas gestores de bases de datos presentan características similares y en esta investigación trataremos algunas de ellas.
DBMS
Es un sistema robusto que es capaz de emplear algoritmos de almacenamiento y recuperación de información para poder implementar un modelo de datos de manera física garantizando que todas las transacciones que se realizan con respecto a dichos datos sean "ácidas" (Atomicity, Consistency, Isolation, Duration).
Para que un DBMS pueda funcionar, primero se debe hacer una instancia de este. Esta instancia está compuesta principalmente de tres componentes:
- Archivos
- Estructuras de memoria.
- Estructuras de procesos.
Cada una de estas estructuras se puede dividir a su vez en diferentes puntos.
Archivos
- Control (ctl): almacenan información acerca de la estructura de archivos de la base.
- Rollback (rbs): cuando se modifica el valor de alguna tupla en una transacción, los valores nuevos y anteriores se almacenan en un archivo, de modo que si ocurre algún error, se puede regresar (rollback) a un estado anterior.
- Redo (rdo): bitácora de toda transacción, en muchos dbms incluye todo tipo de consulta incluyendo aquellas que no modifican los datos.
- Datos (dbf): el tipo más común, almacena la información que es accesada en la base de datos.
- Índices (dbf) (dbi): archivos hermanos de los datos para acceso rápido.
- Temp (tmp): localidades en disco dedicadas a operaciones de ordenamiento o alguna actividad particular que requiera espacio temporal adicional.

- Caché de los Buffers
- Buffer del registro de Redo
- El Pool compartido
- Large Pool
- Java Pool
- Streams Pool
- Caché de diccionario
- Memoria de la sesión para el servidor compartido y el Oracle XA interface (usado donde las transacciones interactúan con más de una base de datos)
- Procesamiento de E/S
- Copias de seguridad y operaciones de recuperación
Oracle accede con frecuencia al diccionario de datos, por lo que tiene dos localizaciones especiales en memoria designadas a mantenerlo. Una de ellas es la caché del diccionario de datos, también conocida como la cache de fila por que contiene datos sobre las filas en vez de los buffers (los cuales contienen bloques de datos), y la otra es el caché de biblioteca.

Estructuras de Proceso
Procesos de usuario: Cada proceso de usuario representa la conexión de un usuario al servidor.
Procesos de segundo plano: El servidor se vale de una serie de procesos que son el enlace entre las estructuras físicas y de memoria.
- SMON
- PMON
- DBWR
- LGWR
- CKPT
- ARCH
- RECO
- LCK
Monitor del sistema (System Monitor, SMON)
Es responsable de efectuar la recuperación de un error cuando se arranca la instancia a continuación de algún tipo de fallo.
Monitor de procesos (Process Monitor, PMON)
Es responsable de controlar los procesos de usuario que accedan a la base de datos y recuperarlos, después de producirse algún error.
Escritor de base de datos (Database Writer, DBWR)
El proceso DBWR es responsable de escribir los bloques modificados (sucio) desde la caché de búfer del SGA a los archivos de datos situados en disco.
Escritor de registro (Log Writer, LGWR)
Es responsable de escribir los datos desde el búfer de registro al archivo de redo.
Punto de control (Checkpoint, CKPT)
Este proceso escribe en los ficheros de control los checkpoints. Estos puntos de sincronización son referencias al estado coherente de todos los ficheros de la BD en un instante determinado, en un punto de sincronización.
Archivador (Archiver, ARCH)
Es responsable de copiar los archivos de registro de rehacer en línea en el soporte de almacenamiento de archivo cuando dichos registros se llenan.
Recuperador (Recoverer, RECO)
Es responsable de efectuar las tareas de limpieza requeridas por las transacciones distribuidas que hayan fallado o que hayan sido suspendidas.
2.2 Estructura física de la base de datos.
En una base de datos almacenamos información relevante para nuestro negocio u organización y desde el punto de vista físico, la base de datos está conformada por dos tipos de archivos.
Archivos de datos: contiene los datos de la base de datos internamente, está compuesto por páginas numeradas secuencialmente que representa la unidad mínima de almacenamiento. Cada página tiene un tamaño de 8kb de información. Existen diferentes tipos de páginas, a tener en cuenta:
- Páginas de datos: es el tipo principal de páginas y son las que almacenan los
registros de datos.
- Páginas de espacio libre (PFS Page Free Space): almacenan información
sobre la ubicación y el tamaño del espacio libre.
- Páginas GAM and SGAM: utilizadas para ubicar extensiones.
- Páginas de Mapa de Ubicaciones de índices (IAM – IndexAllocationMap):
contiene información sobre el almacenamiento de páginas de una tabla o
índice en particular.
- Páginas Índices: Utilizada para almacenar registros de índices.

Datafiles(Archivos de datos): almacenan la información actual de la base de
datos y el diccionario de datos.
- Redo log files(Archivos rehacer): se encarga de almacenar los datos
recuperables en caso de un error grave.
- Control files(Archivos de control) : necesarios para mantener la integridad dela
base de datos.
Además existen archivos externos o auxiliares como lo son:
- Archivos de parámetros :definen algunas características de un instancia de Oracle.
- Archivos de contraseñas : sirven para autentificar a los usuarios
- Copias de archivos rehacer: utilizados para recuperar datos
Datafiles
Son ficheros físicos en los que se almacenan los objetos que forman parte de un tablespace. Un datafile solo pertenece a un tablespace y a una instancia de la base de datos, un tablespace puede estar formado por uno o varios datafiles.
Características:
- Un datafile sólo puede estar asociado con una base de datos.
- Los datafiles reservan automáticamente extensiones cuando se les acaba el espacio.
- Uno o más datafiles forman una unidad lógica de almacenamiento llamada
tablespace.

Archivos de Rehacer (redo log files)
Tienen los cambios que se han hecho a la base de datos para recuperar fallas o para manejar transacciones. Debe estar conformado por dos grupos como mínimo y cada grupo debe estar en discos separados. El principal propósito de estos archivos es servir de respaldo de los datos en la memoria RAM.
Para establecer el tamaño apropiado de un archivo de este tipo deberá considerarse el tamaño del dispositivo que contendrá el respaldo del redo log.
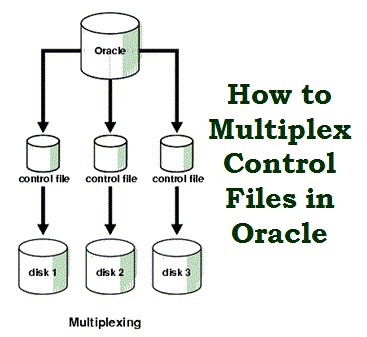
Mínimo deben existir 2, aunque la instalación por defecto es de 3. Se recomienda trabajar con ficheros de Redo Log MULTIPLEXADOS en espejo, de forma que la información es escrita en varios ficheros, a ser posible en distintos discos.

Archivos de Control (Control files)
Tiene la descripción física y dirección de los archivos para el arranque correcto de la base de datos. Mantienen la información física de todos los ficheros que forman la BD, camino incluido; así como el estado actual de la BD. Son utilizados para mantener la consistencia interna y guiar las operaciones de recuperación. Son imprescindibles para que la BD se pueda arrancar y deben encontrarse siempre protegidos. Contienen:
- Información de arranque y parada de la BD.
- Nombres de los archivos de la BD y redo log.
- Información sobre los checkpoints.
- Fecha de creación y nombre de la BD.
- Estado online y offline de los archivos.
2.3 Requerimientos de instalación.
Antes de instalar cualquier SGBD es necesario conocer los requerimientos de
hardware y software, cada SGBD tiene un mínimo de CPU como de memoria RAM para operar adecuadamente, el posible software a desinstalar previamente, verificar el registro de Windows y el entorno del sistema, así como otras características deconfiguración especializadas como pueden ser la reconfiguración de los servicios TCP/IP y la modificación de los tipos archivos HTML para los diversos navegadores.
Otra de las especificaciones que se deben tomar en cuenta es la memoria virtual que se requiere la cual depende de la cantidad de memoria RAM instalada. Si el sistema tiene menos de 4 GB de RAM por lo general el espacio de intercambio debe ser de al menos dos veces este tamaño. Si usted tiene más de 8 GB de memoria RAM instalada puede considerar usar el mismo tamaño como espacio de intercambio.
Cuanta más memoria RAM tenga instalada, es menos probable usar el espacio de intercambio, a menos que tenga un proceso inadecuado.
En general los sistemas gestores solicitan los siguientes requisitos como mínimo ya sea para Windows o Linux:
- RAM 512 MB.
- Memoria virtual 1024 MB.
- Espacio disco duro 1.5 GB.
- Tamaño máximo de la base de datos 4 GB.
- Arquitectura del sistema 32/64 bit.
- El Protocolo de red TCP/IP.
En casos específicos como MongoDB se solicita un mínimo de 1 GB de memoria
RAM y SQLite un mínimo de 2GB de memoria RAM y 9 GB libre de almacenamiento.
2.4 Instalación de un SGBD en modo
transaccional.
Una base de datos en modo transaccional significa que la BD será capaz de que las operaciones de inserción y actualización se hagan dentro de una transacción, es un componente que procesa información descomponiéndola de forma unitaria en operaciones indivisibles, llamadas transacciones, esto quiere decir que todas las operaciones se realizan o no, si sucede algún error en la operación se omite todo el proceso de modificación de la base de datos, si no sucede ningún error se hacen toda la operación con éxito.
Transacciones
Una transacción es un conjunto de líneas de un programa que llevan insert o update o delete. Todo aquél software que tiene una bitácora de transacciones (log que permite hacer operaciones de commit o rollback), propiamente es un software de BD. En todo caso, es un software que emula el funcionamiento de un verdadero software de BD. Cada transacción debe finalizar de forma correcta o incorrecta como una unidad completa. No puede acabar en un estado intermedio.
- Begin Trans para iniciar la transacción
- Commit Trans para efectuar los cambios con éxito
- Rollback Trans para deshacer los cambios
2.5 Variables de Ambiente y archivosimportantes para instalación.
- Extraer el contenido del archivo dentro del directorio de instalación deseado.

- Crear un archivo de opciones

- Elegir un tipo de servidor MySQL.

- Iniciar el servidor MySQL

- Establecer la seguridad de las cuentas de usuario por defecto.

2.6 Procedimiento general de instalación.
El proceso de instalación es muy simple y prácticamente no requiere intervención por parte del usuario.
● Primero nos va a aparecer la ventana de instalación donde nos dan la bienvenida y se le da click en siguiente.

● Después se deben aceptar términos y condiciones.

● Después de haber aceptado los términos y condiciones se elegirá si se requiere todas las funciones de ese gestor o solo unas cuantas.
● Se elige la ubicación para instalar el gestor.
● Se da click en instalar y espera hasta que terminé.

● Una vez terminada la instalación se le da click en terminar y listo, el gestor está instalado.

2.7 Procedimiento para Configuración de un SGBD
Para configurar nuestro SGBD podemos acceder a las siguientes pantallas, para Oracle o MySQL.
El esquema de una base de datos (en inglés, Database Schema) describe la estructura de una Base de datos, en un lenguaje formal soportado por un Sistema administrador de Base de datos (DBMS). En una Base de datos Relacional, el Esquema define sus tablas, sus campos en cada tabla y las relaciones entre cada campo y cada tabla.
Oracle generalmente asocia un 'username' como esquemas en este caso SYSTEM y HR (Recursos humanos).
Por otro lado MySQL presenta dos esquemas information_schema y MySQL ambos guardan información sobre privilegios y procedimientos del gestor y no deben ser eliminados.

Optamos por Detailed Configuration, de modo que se optimice la configuración del servidorMySQL.

Ha llegado un momento crucial. Dependiendo del uso que vayamos a darle a nuestro servidor deberemos elegir una opción u otra, cada una con sus propios requerimientos de memoria. Puede que te guste la opción Developer Machine, para desarrolladores, la más apta para un uso de propósito general y la que menos recursos consume. Si vas a compartir servicios en esta máquina, probablemente Server Machine sea tu elección o, si vas a dedicarla exclusivamente como servidor SQL, puedes optar por Dedicated MySQL Server Machine, pues no te importará asignar la totalidad de los recursos a esta función.

De nuevo, para un uso de propósito general, te recomiendo la opción por defecto, Multifunctional Database.

InnoDB es el motor subyacente que dota de toda la potencia y seguridad a MySQL. Su funcionamiento requiere de unas tablas e índices cuya ubicación puedes configurar. Sin causas de fuerza mayor, acepta la opción por defecto.

Esta pantalla nos permite optimizar el funcionamiento del servidor en previsión del número de usos concurrentes. La opción por defecto, Decision Support (DSS) / OLAP será probablemente la que más te convenga.

Deja ambas opciones marcadas, tal como vienen por defecto. Es la más adecuada para un uso de propósito general o de aprendizaje, tanto si eres desarrollador como no. Aceptar conexiones TCP te permitirá conectarte al servidor desde otras máquinas (o desde la misma simulando un acceso web típico).

Hora de decidir qué codificación de caracteres emplearás, salvo que quieras empezar a trabajar con Unicode porque necesites soporte multilenguaje, probablemente Latin1 te sirva (opción por defecto).

Instalamos MySQL como un servicio de Windows (la opción más limpia) y lo marcamos para que el motor de la base de datos arranque por defecto y esté siempre a nuestra disposición. La alternativa es hacer esto manualmente.
Además, me aseguro de marcar que los ejecutables estén en la variable PATH, para poder invocar a MySQL desde cualquier lugar en la línea de comandos.

Pon una contraseña al usuario root. Esto siempre es lo más seguro.
Si lo deseas, puedes indicar que el usuario root pueda acceder desde una máquina diferente a esta, aunque debo advertirte de que eso tal vez no sea una buena práctica de seguridad.

Última etapa, listos para generar el fichero de configuración y arrancar el servicio.
Sólo damos al botón de Finalizar y terminamos con la configuración del DBMS.

2.8 Comandos generales de alta y baja del SGBD
Una tabla es un sistema de elementos de datos (atributo - valores) que se organizan, que usando un modelo vertical - columnas (que son identificados por su nombre)- y horizontal filas. Una tabla tiene un número específico de columnas, pero puede tener cualquier número de filas. Cada fila es identificada por los valores que aparecen en un subconjunto particular de la columna que se ha identificado por una llave primaria.
Una tabla de una base de datos es similar en apariencia a una hoja de cálculo, en cuanto a que los datos se almacenan en filas y columnas. Como consecuencia, normalmente es bastante fácil importar una hoja de cálculo en una tabla de una base de datos. La principal diferencia entre almacenar los datos en una hoja de cálculo y hacerlo en una base de datos es la forma de organizarse los datos.

A nivel de tabla: Refieren a una o a varias columnas, donde cada columna se define individualmente.

A nivel de Columna el nombre de la columna puede tener un máximo de 30 caracteres.
En Oracle podemos implementar diversos tipos de tablas. A continuación se presenta una recopilación no exhaustiva de ellas.

La sintaxis del comando que permite crear un tabla es la siguiente
Del examen de la sintaxis de la sentencia CreateTable se puede concluir que necesitamos conocer los distintos tipos de columna y las distintas restricciones que se pueden imponer al contenido de las columnas.
Conclusiones
En conclusión, las estructuras de la memoria es un grupo de estructuras de la memoria compartida que contiene datos e información de control de una instancia de una BD. Si varios usuarios se conectan de forma concurrente a la misma instancia, entonces los datos se comparten en el SGA, por lo que también se llama shared global área y que cada proceso de usuario representa la conexión de un usuario al servidor. Procesos de segundo plano: El servidor se vale de una serie de procesos que son el enlace entre las estructuras físicas y de memoria.
La estructura fisica y logica se complementan la una a otra, son dos partes muy importantes de las bases de datos, la estructura física corresponde a los ficheros del sistema operativo, cada estructura física puede cambiar un poco dependiendo del cual SGBD se esté usando pero en esencia su funcionamiento es el mismo y no difieren unos con otros.
Gracias al avance tecnológico se ha podido lograr que los sistemas de gestión de bases de datos utilicen menos recursos que en otras épocas y aún así nos ofrezcan múltiples funciones sin la necesidad de cambiar algún componente o tener que actualizar totalmente el equipo para poder hacer uso de los gestores además de que la mayor parte de los sistemas gestores solicitan los mismo recursos aunque en algunos casos solicitan algún requisito extra.
Tener un SGBD en modo transaccional es muy importante, el poder procesar bloques de código con varias operaciones ligadas entre sí, y además con esa seguridad que caracteriza a las transacciones de poder deshacer cambios si se presenta algún error, hace posible resolver problemas que con otros métodos simplemente no es posible o no son para nada confiables.
Para instalar MySQL como primer instancia el archivo primordial es el que se descarga de la Web de MySQL. El proceso para instalar MySQL desde un archivo ZIP La instalación no es muy complicada como se pudo observar y gracias a eso se nos facilita tener un gestor en nuestras computadoras.
La configurancion de un SBGD de base de datos depende principalmente de dos variables, la primera es el tipo de SGBD y el segunda es el uso que se le quiera dar. En general las Bases de Datos, al menos manejadas en MYSQL, son tablas parecidas a las que usamos en excel, columnas y filas, cabe mencionar que para eliminar un registro, tabla se usa el lenguaje SQL, DELETE TABLE, o para crear una nueva tabla, CREATE TABLE.
Bibliografía
Unknown. (2021, July 19). 2.1.1 Estructura de memoria y procesos de la instancia(RESUMEN). Blogspot.com.https://yesenializbethguerrerogarcia.blogspot.com/2017/04/211-estructura-de-memoria-y-procesos-de.htmlArquitectura física — documentación de Bases de Datos I | Proyecto II - 0.0.1. (2016).Readthedocs.io. https://manual-tecnico-bd-oracle.readthedocs.io/es/latest/Arquitectura%20fisica.htmlestructurafisicabd2. (2015, October 9). Estructura física de una base de datos. Busine-Strat-Blog-Es. https://estructurafisicabd2.wixsite.com/busine-strat-blog-es/single-post/2015/10/09/estructura-f%C3%ADsica-de-una-base-de-datosUnknown. (2021, July 19). 2.2 Estructura física de la base de datos. Blogspot.com.http://mariaconcepciongomezlopez.blogspot.com/2017/03/22-estructura-fisica-de-la-base-de-datos.htmlUNIDAD 2 :: Administracion Bases de Datos. (2012). Webnode.mx.https://proyecto359.webnode.mx/unidad2/Unknown. (2021, July 19). 1.1 Requerimientos e instalación del SGBD. Blogspot.com.http://lopez-garcia-victor.blogspot.com/2012/08/11-requerimientos-e-instalacion-del- sgbd.htmlMongoDB disk and memory requirements. (2015, November 17). Documentation & User Guides | FotoWare.https://learn.fotoware.com/On-Premises/FotoWeb/05_Configuring_sites/Setting_the_MongoDB_instance_that_FotoWeb_uses/MongoDB_disk_and_memory_requirementsUNIDAD 2. (2021). Portafolio de Evidencias. https://administracionbd.weebly.com/unidad- 2.htmlRequerimientos para la instalación del SGBD, instalación del SGBD en modo transaccional. (n.d.).StuDocu. Retrieved July 19, 2021, from https://www.studocu.com/es-mx/document/instituto-tecnologico-de-tijuana/administracion-de-base-de-datos/requerimientos-para-la-instalacion-del-sgbd-instalacion-del-sgbd-en-modo-transaccional/11544042Meyli. (2021, July 19). 2.1.5 Variables de Ambiente y Archivos Importantes para Instalación.Blogspot.com. http://meylialejandrarobleromora.blogspot.com/2017/05/215-variables-de-ambiente-y-archivos.htmlVariables de Ambiente y Archivos Importantes de Instalacion. (2021). Scribd.https://es.scribd.com/presentation/338827029/Variables-de-Ambiente-y-Archivos-Importantes-de-InstalacionGestor. (2021). Unidad 2: Arquitectura del Gestor - Administración de Bases de Datos.Google.com. https://sites.google.com/site/itjabd23/home/asignatura/plan-de-estudios/unidad-2-arquitectura-del-gestorGestor. (2021). Unidad 2: Arquitectura del Gestor - Administración de Bases de Datos.Google.com. https://sites.google.com/site/itjabd23/home/asignatura/plan-de-estudios/unidad-2-arquitectura-del-gestorGomez, L. (2021, July 19). Unidad 2 Arquitectura del gestor. Blogspot.com.http://itmlauragomezadmdebasededatos.blogspot.com/2016/05/unidad-2-arquitectura- del-gestor.htmlUnknown. (2021, July 19). 2.8 Comandos generales de alta y baja del SGBD. Blogspot.com.https://mariaconcepciongomezlopez.blogspot.com/2017/03/28-comandos-generales-de-alta-y-baja.htmlObservaciones: Todos los integrantes del equipo trabajaron.
Comentarios
Publicar un comentario